Dijkstra's algorithm
 Dijkstra's algorithm runtime |
|
| Class | Search algorithm |
|---|---|
| Data structure | Graph |
| Worst case performance | 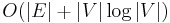 |
| Graph and tree search algorithms |
|---|
Search
|
| More |
Related
|
Dijkstra's algorithm, conceived by Dutch computer scientist Edsger Dijkstra in 1956 and published in 1959,[1][2] is a graph search algorithm that solves the single-source shortest path problem for a graph with nonnegative edge path costs, producing a shortest path tree. This algorithm is often used in routing. An equivalent algorithm was developed by Edward F. Moore in 1957.[3]
For a given source vertex (node) in the graph, the algorithm finds the path with lowest cost (i.e. the shortest path) between that vertex and every other vertex. It can also be used for finding costs of shortest paths from a single vertex to a single destination vertex by stopping the algorithm once the shortest path to the destination vertex has been determined. For example, if the vertices of the graph represent cities and edge path costs represent driving distances between pairs of cities connected by a direct road, Dijkstra's algorithm can be used to find the shortest route between one city and all other cities. As a result, the shortest path first is widely used in network routing protocols, most notably IS-IS and OSPF (Open Shortest Path First).
Contents |
Algorithm
Let the node at which we are starting be called the initial node. Let the distance of node Y be the distance from the initial node to Y. Dijkstra's algorithm will assign some initial distance values and will try to improve them step by step.
- Assign to every node a distance value. Set it to zero for our initial node and to infinity for all other nodes.
- Mark all nodes as unvisited. Set initial node as current.
- For current node, consider all its unvisited neighbors and calculate their tentative distance (from the initial node). For example, if current node (A) has distance of 6, and an edge connecting it with another node (B) is 2, the distance to B through A will be 6+2=8. If this distance is less than the previously recorded distance (infinity in the beginning, zero for the initial node), overwrite the distance.
- When we are done considering all neighbors of the current node, mark it as visited. A visited node will not be checked ever again; its distance recorded now is final and minimal.
- If all nodes have been visited, finish. Otherwise, set the unvisited node with the smallest distance (from the initial node) as the next "current node" and continue from step 3.
Description
- Note: For ease of understanding, this discussion uses the terms intersection, road and map -- however formally these terms are vertex, edge and graph respectively.
Suppose you want to find the shortest path between two intersections on a city map, a starting point and a destination. The order is conceptually simple: to start, mark the distance to every intersection on the map with infinity. This is done to not to imply there is an infinite distance, but to note that that intersection has not yet been visited. (Some variants of this method simply leave the intersection unlabeled.) Now, at each iteration, select a current intersection. For the first iteration the current intersection will be the starting point and the distance to it (the intersection's label) will be zero. For subsequent iterations (after the first) the current intersection will be the closest unvisited intersection to the starting point—this will be easy to find.
From the current intersection, update the distance to every unvisited intersection that is directly connected to it—this is done by relabeling the intersection with the minimum of its current value and value of the current intersection plus the distance between. In effect, the intersection is relabeled if the path to it, through the current intersection is shorter than the previously known paths. To facilitate shortest path identification, in pencil, mark the road with an arrow pointing to the relabeled intersection if you label/relabel it, and erase all others pointing to it. After you have updated the distances to each neighboring intersection, mark the current intersection as visited and select the unvisited intersection with lowest distance (from the starting point) -- or lowest label—as the current intersection. Nodes marked as visited are labeled with the shortest path from the starting point to it and will not be revisited or returned to.
Continue this process of updating the neighboring intersections with the shortest distances, then marking the current intersection as visited and moving onto the closest unvisited intersection until you have marked the destination as visited. Once you have marked the destination as visited (as is the case with any visited intersection) you have determined the shortest path to it, from the starting point, and can trace your way back, following the arrows in reverse.
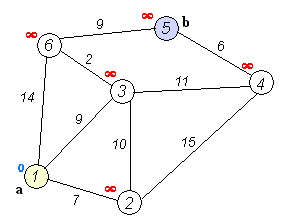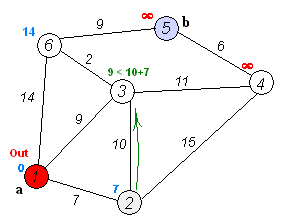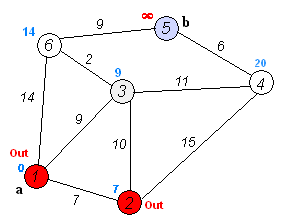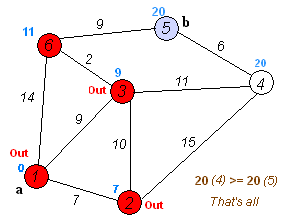
In the accompanying animated graphic, the starting and destination intersections are colored in light pink and blue and labelled a and b respectively. The visited intersections are colored in red, and the current intersection in a pale blue.
Of note is the fact that this algorithm makes no attempt to direct "exploration" towards the destination as one might expect. Rather, the sole consideration in determining the next "current" intersection is it's distance from the starting point. In some sense, this algorithm "expands outward" from the starting point, iteratively considering every node that is closer in terms of shortest path distance until it reaches the destination. When understood in this way, it is clear how the algorithm necessarily finds the shortest path, however it may also reveal one of the algorithms weaknesses, it's relative slowness in some topologies.
Pseudocode
In the following algorithm, the code u := vertex in Q with smallest dist[], searches for the vertex u in the vertex set Q that has the least dist[u] value. That vertex is removed from the set Q and returned to the user. dist_between(u, v) calculates the length between the two neighbor-nodes u and v. The variable alt on line 13 is the length of the path from the root node to the neighbor node v if it were to go through u. If this path is shorter than the current shortest path recorded for v, that current path is replaced with this alt path. The previous array is populated with a pointer to the "next-hop" node on the source graph to get the shortest route to the source.
1 function Dijkstra(Graph, source):
2 for each vertex v in Graph: // Initializations
3 dist[v] := infinity // Unknown distance function from source to v
4 previous[v] := undefined // Previous node in optimal path from source
5 dist[source] := 0 // Distance from source to source
6 Q := the set of all nodes in Graph
// All nodes in the graph are unoptimized - thus are in Q
7 while Q is not empty: // The main loop
8 u := vertex in Q with smallest dist[]
9 if dist[u] = infinity:
10 break // all remaining vertices are inaccessible from source
11 remove u from Q
12 for each neighbor v of u: // where v has not yet been removed from Q.
13 alt := dist[u] + dist_between(u, v)
14 if alt < dist[v]: // Relax (u,v,a)
15 dist[v] := alt
16 previous[v] := u
17 return dist[]
If we are only interested in a shortest path between vertices source and target, we can terminate the search at line 11 if u = target. Now we can read the shortest path from source to target by iteration:
1 S := empty sequence 2 u := target 3 while previous[u] is defined: 4 insert u at the beginning of S 5 u := previous[u]
Now sequence S is the list of vertices constituting one of the shortest paths from target to source, or the empty sequence if no path exists.
A more general problem would be to find all the shortest paths between source and target (there might be several different ones of the same length). Then instead of storing only a single node in each entry of previous[] we would store all nodes satisfying the relaxation condition. For example, if both r and source connect to target and both of them lie on different shortest paths through target (because the edge cost is the same in both cases), then we would add both r and source to previous[target]. When the algorithm completes, previous[] data structure will actually describe a graph that is a subset of the original graph with some edges removed. Its key property will be that if the algorithm was run with some starting node, then every path from that node to any other node in the new graph will be the shortest path between those nodes in the original graph, and all paths of that length from the original graph will be present in the new graph. Then to actually find all these short paths between two given nodes we would use a path finding algorithm on the new graph, such as depth-first search.
Running time
An upper bound of the running time of Dijkstra's algorithm on a graph with edges  and vertices
and vertices 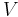 can be expressed as a function of
can be expressed as a function of 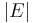 and
and 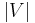 using the Big-O notation.
using the Big-O notation.
For any implementation of set  the running time is
the running time is 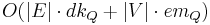 , where
, where 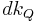 and
and 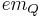 are times needed to perform decrease key and extract minimum operations in set , respectively.
are times needed to perform decrease key and extract minimum operations in set , respectively.
The simplest implementation of the Dijkstra's algorithm stores vertices of set in an ordinary linked list or array, and extract minimum from is simply a linear search through all vertices in . In this case, the running time is 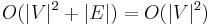 .
.
For sparse graphs, that is, graphs with far fewer than 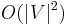 edges, Dijkstra's algorithm can be implemented more efficiently by storing the graph in the form of adjacency lists and using a binary heap, pairing heap, or Fibonacci heap as a priority queue to implement extracting minimum efficiently. With a binary heap, the algorithm requires
edges, Dijkstra's algorithm can be implemented more efficiently by storing the graph in the form of adjacency lists and using a binary heap, pairing heap, or Fibonacci heap as a priority queue to implement extracting minimum efficiently. With a binary heap, the algorithm requires 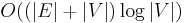 time (which is dominated by
time (which is dominated by 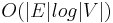 , assuming the graph is connected), and the Fibonacci heap improves this to .
, assuming the graph is connected), and the Fibonacci heap improves this to .
Related problems and algorithms
The functionality of Dijkstra's original algorithm can be extended with a variety of modifications. For example, sometimes it is desirable to present solutions which are less than mathematically optimal. To obtain a ranked list of less-than-optimal solutions, the optimal solution is first calculated. A single edge appearing in the optimal solution is removed from the graph, and the optimum solution to this new graph is calculated. Each edge of the original solution is suppressed in turn and a new shortest-path calculated. The secondary solutions are then ranked and presented after the first optimal solution.
Dijkstra's algorithm is usually the working principle behind link-state routing protocols, OSPF and IS-IS being the most common ones.
Unlike Dijkstra's algorithm, the Bellman-Ford algorithm can be used on graphs with negative edge weights, as long as the graph contains no negative cycle reachable from the source vertex s. (The presence of such cycles means there is no shortest path, since the total weight becomes lower each time the cycle is traversed.)
The A* algorithm is a generalization of Dijkstra's algorithm that cuts down on the size of the subgraph that must be explored, if additional information is available that provides a lower bound on the "distance" to the target. This approach can be viewed from the perspective of linear programming: there is a natural linear program for computing shortest paths, and solutions to its dual linear program are feasible if and only if they form a consistent heuristic (speaking roughly, since the sign conventions differ from place to place in the literature). This feasible dual / consistent heuristic defines a nonnegative reduced cost and A* is essentially running Dijkstra's algorithm with these reduced costs. If the dual satisfies the weaker condition of admissibility, then A* is instead more akin to the Bellman-Ford algorithm.
The process that underlies Dijkstra's algorithm is similar to the greedy process used in Prim's algorithm. Prim's purpose is to find a minimum spanning tree for a graph.
Dynamic programming perspective
From a dynamic programming point of view, Dijkstra's algorithm is a successive approximation scheme that solves the dynamic programming functional equation for the shortest path problem by the Reaching method.[4][5]
In fact, Dijkstra's explanation of the logic behind the algorithm,[6] namely
Problem 2. Find the path of minimum total length between two given nodes
and
We use the fact that, if
is a node on the minimal path from
is a paraphrasing of Bellman's famous Principle of Optimality in the context of the shortest path problem.
See also
- Breadth-first search
- D* search algorithm
- Depth-first search
- Euclidean shortest path
- Floyd–Warshall algorithm
- Flood fill
- Longest path problem
Notes
- ↑ Dijkstra, Edsger; Thomas J. Misa, Editor (2010-08). "An Interview with Edsger W. Dijkstra". Communications of the ACM 53 (8): 41–47. "What is the shortest way to travel from Rotterdam to Groningen? It is the algorithm for the shortest path which I designed in about 20 minutes. One morning I was shopping with my young fianceé, and tired, we sat down on the café terrace to drink a cup of coffee and I was just thinking about whether I could do this, and I then designed the algorithm for the shortest path.".
- ↑ Dijkstra 1959
- ↑ Moore, E.F. (1959). "The shortest path through a maze". Proceedings of an International Symposium on the Theory of Switching (Cambridge, Massachusetts, 2–5 April 1957). Cambridge: Harvard University Press. pp. 285–292.
- ↑ Sniedovich, M. (2006). "Dijkstra’s algorithm revisited: the dynamic programming connexion" (PDF). Journal of Control and Cybernetics 35 (3): 599–620. http://matwbn.icm.edu.pl/ksiazki/cc/cc35/cc3536.pdf. Online version of the paper with interactive computational modules.
- ↑ Denardo, E.V. (2003). Dynamic Programming: Models and Applications. Mineola, NY: Dover Publications. ISBN 978-0486428109.
- ↑ Dijkstra 1959, p. 270
References
- Dijkstra, E. W. (1959). "A note on two problems in connexion with graphs". Numerische Mathematik 1: 269–271. http://www-m3.ma.tum.de/twiki/pub/MN0506/WebHome/dijkstra.pdf.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). "Section 24.3: Dijkstra's algorithm". Introduction to Algorithms (Second ed.). MIT Press and McGraw-Hill. pp. 595–601. ISBN 0-262-03293-7.
- Zhan, F. Benjamin; Noon, Charles E. (February 1998). "Shortest Path Algorithms: An Evaluation Using Real Road Networks". Transportation Science 32 (1): 65–73. doi:10.1287/trsc.32.1.65.
External links
- Oral history interview with Edsger W. Dijkstra, Charles Babbage Institute University of Minnesota, Minneapolis.
- Dijkstra's Algorithm in C#
- Applet by Carla Laffra of Pace University
- Animation of Dijkstra's algorithm
- Visualization of Dijkstra's Algorithm
- Shortest Path Problem: Dijkstra's Algorithm
- Dijkstra's Algorithm Applet
- Open Source Java Graph package with implementation of Dijkstra's Algorithm
- Java Implementation of Dijkstra's Algorithm on AlgoWiki
- QuickGraph, Graph Data Structures and Algorithms for .NET
- Implementation in Boost C++ library
- Implementation in T-SQL
- A Java library for path finding with Dijkstra's Algorithm and example applet
- A MATLAB program for Dijkstra's algorithm